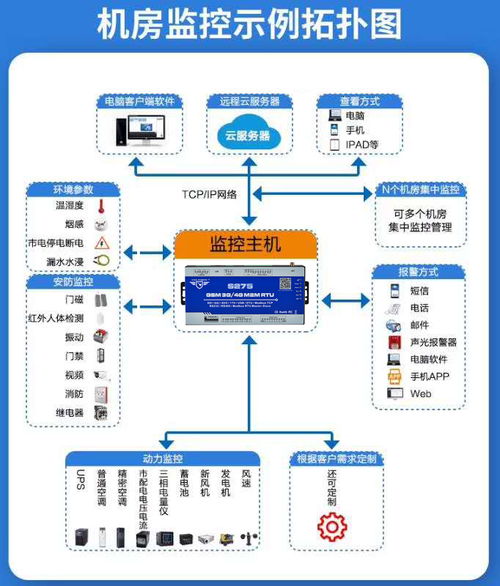
随着科学计算、人工智能和大数据分析等领域的飞速发展,对计算能力的需求呈现指数级增长。单个计算节点已无法满足巨量并行任务的需求,因此,由成百上千甚至更多节点协同工作的高性能计算集群应运而生。而在集群系统中,负责连接所有计算节点、存储设备,并确保数据高效、可靠流通的网络,是决定整个集群性能与效率的基石。高性能计算集群网络技术的开发,正是聚焦于构建这一核心神经系统。
高性能计算网络与传统数据中心网络存在显著区别。其核心设计目标是极低的延迟和极高的带宽,以满足大规模并行计算中频繁的进程间通信需求。例如,在气象模拟或分子动力学仿真中,数以万计的进程需要同步交换中间数据,网络延迟的细微增加都可能被放大,导致整体计算时间大幅延长。因此,HPC网络技术开发的首要挑战是突破传统网络协议栈(如TCP/IP)的开销瓶颈。
目前,主流的HPC网络技术围绕专用互连架构展开,主要包括:
- InfiniBand:作为高性能计算领域的霸主,InfiniBand通过提供远程直接内存访问、内核旁路等技术,实现了极低的通信延迟和极高的吞吐量。其开发重点在于不断提升单端口带宽(目前已达400Gb/s及以上)、增强网络管理软件以及对新应用模式(如异构计算)的支持。
- Omni-Path Architecture:英特尔推出的OPA旨在与InfiniBand竞争,它提供了类似的性能特性,并在可扩展性和成本方面进行了优化设计。其技术开发侧重于与英特尔处理器及软件的深度集成。
- 高性能以太网:随着RoCE和iWARP等技术的成熟,基于以太网的RDMA正在侵蚀传统HPC网络市场。它允许在熟悉的以太网基础设施上获得接近InfiniBand的性能,大幅降低了部署和运维门槛。开发焦点在于完善拥塞控制、提升大规模部署下的稳定性以及与云环境的融合。
- 定制化互连技术:在顶尖的超算系统中,如富士通的Tofu互连D用于“富岳”,或Cray的Slingshot技术,这些定制网络与计算架构紧密结合,实现了极致的优化。其开发是高度定制化的系统级工程。
网络技术的开发不仅限于硬件。软件栈,特别是通信库,发挥着至关重要的作用。MPI作为HPC并行编程的事实标准,其网络层实现必须与底层硬件深度协同,以充分发挥硬件能力。开发更智能的通信调度算法、支持新的编程模型(如PGAS),以及优化集体操作(如Allreduce)的性能,是软件层面的核心课题。随着计算与存储的融合,支持并行文件系统的高性能数据访问网络也成为开发重点。
HPC网络技术开发面临几大趋势与挑战:
- 异构计算支持:集群中GPU、FPGA等加速器日益普及,网络需要提供GPU Direct RDMA等技术,实现加速器内存之间的直接数据交换,避免不必要的CPU拷贝开销。
- 可扩展性与成本平衡:如何在数万乃至百万节点规模下保持低延迟和高带宽,同时控制成本和功耗,是持续性的挑战。
- 与云和人工智能的融合:公有云开始提供HPC服务,AI训练对通信模式提出了新要求(如参数服务器、All-Reduce),网络技术需要适应这些混合负载。
- 智能网络操作:利用AI进行网络性能预测、故障诊断和自动优化,是实现高效运维的下一代方向。
高性能计算集群网络技术的开发是一个硬件与软件深度协同、持续追求极致性能与效率的前沿领域。它不仅是连接计算节点的电缆,更是释放集群巨算力的关键使能器,其进步将直接推动科学研究与工程创新的边界不断拓展。